Summary:
The article describes the part of the speech recognition system design in the family monitoring robot project. Through the parallel processing of DSP, DMA and ARM Cortex-A8, and using the double buffering method, the real-time speech recognition system based on ATK is implemented on embedded Linux. The software and hardware of the system are designed in this paper. In terms of hardware, the hardware composition principle of the speech recognition system is given, and the schematic diagrams of key parts are provided; in terms of software, the method of real-time speech recognition is proposed, and the application implementation process is given. Finally, the speech recognition experiment was carried out by speaking with real people. The real-time speech recognition rate reached more than 94.67%. The experiment verified the correctness of the system's software and hardware design.
Voice is the most commonly used communication method for human beings, and the most desired way for humans and computers to communicate. Therefore, using speech to communicate with computers has also become a hot topic of recent research. The understanding of speech by computers is an attractive and challenging subject in computer science.
In the 1990s, with the advent of the multimedia era, the voice recognition system was urgently required to move from the laboratory to the practical. Many developed countries such as the United States, Japan, South Korea, and famous companies such as IBM, Apple, AT & T, NTT, etc. have invested heavily in the practical development and research of speech recognition systems. IBM developed the Chinese ViaVoice speech recognition system in 1997, and the following year developed a speech recognition system ViaVoice '98 that can recognize local accents such as Shanghai dialect, Cantonese dialect and Sichuan dialect. Currently, voice recognition telephones and voices have appeared on the market Identify products such as notepads, such as Voice Organizer of VPTC in the United States and Parrot in France.
China's speech recognition research started late, but it has developed rapidly in recent years and has been keeping up with the international level. The country also attaches great importance to it, and has included large vocabulary speech recognition research in the "8 63" plan , Institute of Automation, Department of Electronic Engineering, Tsinghua University, Peking University and other units have achieved high-level scientific research results, such as the non-specific person, continuous voice dictation system and Chinese voice man-machine dialogue system developed by the Institute of Automation of the Chinese Academy of Sciences. Rate or system response rate can reach more than 90%. In view of China's huge future market, foreign countries also attach great importance to the study of Chinese speech recognition. The United States, Singapore and other places have gathered a group of scholars from mainland China, Taiwan, Hong Kong and other places, and their research results have reached a fairly high level.
1 System design
The text is the design part of the voice recognition system in the home monitoring robot project. The design purpose is to design a robot that can recognize voice and help monitor the family with inconvenient people. In order to realize the speech recognition system, a block diagram of the overall structure of the speech recognition system is designed, as shown in Figure 1.
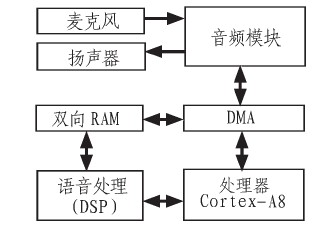
Figure 1 Block diagram of the overall structure of the system
1.1 Hardware design
The functions studied and designed in this article are all applied to mobile robots. Therefore, the research and design of the system needs to take into account the characteristics of small size, power saving, and ease of movement, and a friendly display interface that is convenient for home users to operate. For the voice recognition part, a processor, voice acquisition circuit, and voice output circuit for voice recognition algorithm processing are required, as shown in Figure 2. Among them, the processor of the voice recognition algorithm is mainly responsible for the arithmetic processing of the algorithm, which is equivalent to the brain of the robot; the voice collection circuit is responsible for collecting external sound signals, which is equivalent to the ear of the robot; the voice output circuit is responsible for outputting the speech sound, which is equivalent to the mouth of the robot .
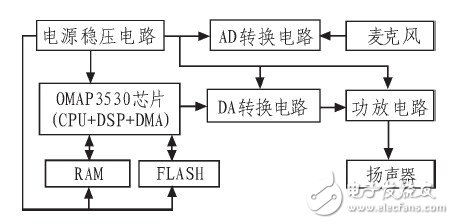
Figure 2 System hardware structure diagram
1) Voice recognition algorithm processor selection
According to the requirements of system design functions, currently commonly used types of speech recognition chips are: single chip microcomputer (MCU), DSP and SoC (System on Circuit). Considering the shortage of resources of ordinary single chip microcomputer (MCU) and the shortcomings of slower running speed, the design of this system will not consider the use of single chip microcomputer (MCU) as the processor of speech recognition. DSP contains special components used for digital signal processing. It has strong computing power and high precision. However, the current price of DSP is relatively high. At the same time, considering the characteristics of this system, it is necessary to choose one that has strong computing power and is suitable for speech recognition. Function, and can achieve a better user interface, with a file system (used to identify maps) function, so it is not wise to choose DSP. At present, Texas Instruments has introduced a new chip OMAP3530, which has a dual-core ARM CortexTM-A8 core and a TMS320C64 + TM DSP core. It belongs to the high-performance OMAP35x architecture series and meets the various functional characteristics of system design.
2) Voice codec chip selection
It is very important for the robot to choose a suitable voice processing chip. Considering that various power supplies are used in the system and the power supply needs to be managed, it is very appropriate to select the TPS 65930 chip provided by TI as the hardware platform for the audio codec processing function of the voice recognition part of the system. The chip is a chip that integrates power management, ADC, embedded power control (EPC), and full-featured audio codec. It meets the needs of all power management and audio codec of the system, saving the design PCB board. This saves space and reduces wiring troubles for multi-power hardware design.
3) Circuit design
The design of this article is used in mobile robots, so it needs the functions of voice input, recognition processing and voice output. For voice input collection, this article uses a sound sensor microphone and peripheral circuits to achieve. For the voice output part, a power amplifier is used in combination with a speaker. The schematic diagram of the design voice part is shown in Figure 3.
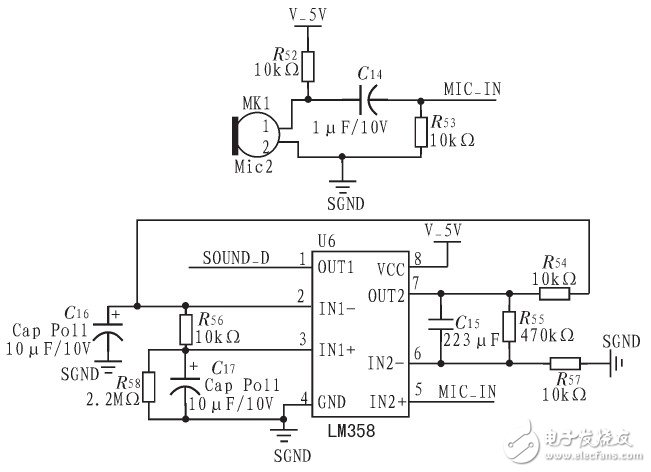
Figure 3 Schematic diagram of voice input
Bone Conduction Helmet Bluetooth Speaker
Bone Conduction Helmet Bluetooth Speaker,Music Player Speaker,Waterproof Bone Conduction Headset,Bone Conduction Headset Brand
Shenzhen Lonfine Innovation Technology Co., Ltd , https://www.lonfinesmart.com